
Context
I was recently tasked with optimizing stockinsights.ai’s full text search system for one of our core features: keyword search over filings.
Previously, this worked by storing entire documents as raw strings in MongoDB and scanning through them at query time to return surrounding snippets. As you can imagine, this approach became increasingly slow and inefficient as the number of filings kept growing.
This clearly needed to be fixed.
While looking at the existing system, I noticed that we already stored chunked text snippets in a separate Postgres instance as part of our embeddings tables for semantic search. Each chunk already existed as a row, paired with an embedding.
It seemed obvious that we should reuse this same chunked data for keyword search as well.
At a high level, the idea looked something like this:
plaintextKeyword search across snippets → return matching text chunks → rank documents higher if more chunks match → return one representative snippet per document
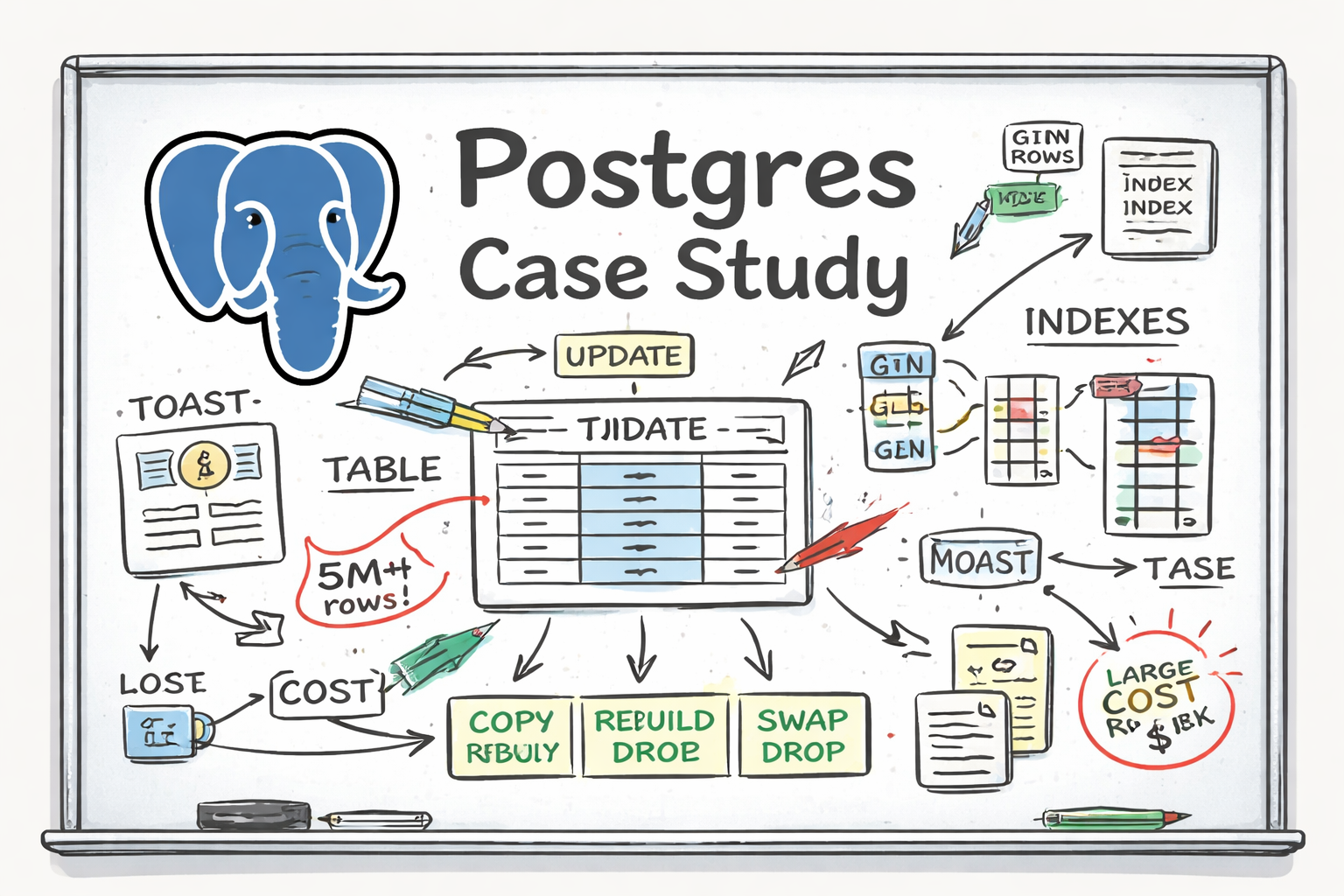
All I needed to do, or so I thought, was add another column to store tsvectors (Postgres’s internal data structure for full text search) and create a GIN index on top of it.
How hard could it be?
The obvious solution
Postgres has built-in full text search using tsvector and tsquery. The plan was straightforward:
- Add a
tsvectorcolumn to the embeddings table - Populate it from the existing text column
- Create a GIN index
- Query snippets directly instead of scanning raw documents
Note: We could have normalized this into a separate table, but at a startup, we often accept some denormalization in favor of simpler systems.
From an application point of view, this was almost trivial. No new data model, no new pipeline, just reuse what already existed.
The mistake was assuming that a small logical change would translate into a small physical change inside the database.
When the costs showed up
Initially, nothing failed. The migration just took much longer than expected.
Each document type table had roughly 2 to 5 million rows. Updating even 10,000 rows was taking hours, and each iteration made the next one slower. What started as a small backfill quickly turned into something that felt unbounded in cost.
Populating the new column dragged on, disk usage grew far beyond what the additional data alone could justify, and creating the GIN index noticeably impacted write throughput while it was running.
More concerning was that queries themselves began to slow down. Reads that were previously fast started degrading as the table and indexes bloated, even though the query plans hadn’t meaningfully changed.
At that point, it was clear that something deeper was going on.
UPDATE in Postgres is not mutation
Postgres stores tables as heap files. A heap file is an unordered collection of tuples, and tuples are immutable.
When you run an UPDATE, Postgres does not modify a row in place. Instead, it:
- Inserts a new version of the row
- Marks the old version as no longer visible
- Leaves cleanup for later
This design exists to support MVCC (multi-version concurrency control), which allows readers and writers to operate concurrently by keeping multiple versions of rows and resolving visibility at read time.
In practice, this means UPDATE is not a mutation of an existing row, but the creation of a new version of that row.
Why adding a column rewrites every row
A Postgres row is stored as a single physical tuple containing all columns. What I learned here is that there is no column-level storage, and therefore no partial row update.
When you populate a new column on an existing table, Postgres must:
- Copy every existing column value
- Append the new column value
- Write an entirely new tuple
Even if every other column remains unchanged, the entire row is rewritten. On a large table, this effectively means rewriting the entire dataset, not just adding one column.
Why text, tsvector, and embeddings make this worse
Our table already stored text snippets and embeddings, and we were about to add tsvectors on top of that.
A few things compound the cost here:
- Text columns are variable length. Large values often exceed the inline storage limit. When that happens, Postgres uses TOAST.
TOAST stores oversized column values out of line and keeps pointers to them in the main tuple.
Even when data is TOASTed, updating the row still requires rewriting the main tuple and, in some cases, the TOAST entries themselves.
-
tsvectorexpands data. It is not just the original text. It stores lexemes (similar to tokens) along with positional metadata, and it is also typically stored via TOAST. -
Embeddings make rows wide. Embeddings are large binary float arrays stored alongside text and indexed separately. Combined with text and
tsvector, each row becomes wide, and wide rows are expensive to rewrite.
This combination pushes right up against the limits of what an immutable row store is comfortable handling.
Indexes amplify the cost
On top of this, the table already had indexes.
Every new tuple version requires index maintenance. For each index, Postgres must:
- Insert new index entries
- Maintain index structure
- Write corresponding WAL records
GIN indexes are especially heavy. A single row can generate many index entries, often one per token in the tsvector.
While most indexes in Postgres are B-tree based, GIN indexes are inverted indexes.
WAL (write-ahead log) is the sequential log used for crash recovery and replication. More index work means more WAL traffic, which directly affects disk usage, replication lag, and write latency.
Indexes make reads fast, but they multiply write cost. That tradeoff is unavoidable.
An alternate approach: COPY, swap, drop
While digging through Postgres blogs and discussions, I came across an alternative approach for modifying very large tables.
Instead of updating the table in place, you:
- Create a new table with the desired schema
- Copy data into it
- Recreate indexes
- Swap it with the old table
- Drop the old table
The COPY-swap-drop approach.
This has a few important properties:
- Each row is written exactly once
- No dead tuples are created
- Indexes are built cleanly
- There is no incremental index maintenance during updates
By contrast, UPDATE creates deferred work. Dead tuples accumulate and must be cleaned up later, and indexes are updated repeatedly for each new row version.
In an immutable storage model, rewriting data cleanly can often be cheaper than mutating it incrementally.
Final design
One additional factor that helped was simply scaling the RDS instance. More memory meant more rows could be processed efficiently during the rebuild, which significantly reduced runtime.
The final workflow looked like this:
- Upgrade the instance
- Use COPY-swap-drop to rebuild the table
- Recreate indexes
This approach ended up being far faster and more predictable than trying to UPDATE rows in place.